
AI-driven testing just got smarter. Discover SOAtest 2025.1. >>
Jump to Section
Measuring Code Coverage: Guide to Effective Testing

November 20, 2023
10 min read
Code coverage depends heavily on precision. It entails choosing only the appropriate coverage required for your project. The two major code coverage pitfalls are thoroughly discussed in this article, along with how to prevent them.
Jump to Section
Jump to Section
What Is Code Coverage?
The essence of code coverage is exposing code that has not been executed from having performed your software testing. Uncovered code makes it obvious where there may be defects lurking in the application and that you have missing test cases to address these uncovered areas.
The most common approach in monitoring the code as it executes and attaining code coverage is by instrumenting the code. This means that the existing code is adorned with additional code and can be further tailored to detect if coding structures like a statement, function, condition, decision, branch, and others have been executed. This is important because there will be various logical paths of execution that can be taken, so you want to make sure you have exercised them and exposed unsafe, insecure, or unpredictable behavior.
Benefits of Measuring Code Coverage
You don’t want coverage for coverage’s sake. You need meaningful coverage that indicates that you’ve done a good job testing the software. Besides finding gaps in your testing, code coverage also exposes dead code.
Dead code is code that exists in the application, but there’s no possible execution scenario for that code to ever get exercised. Sometimes our requirements change, so we alter the logic. In complex software systems, we don’t realize every outcome and effect, such as now having a function or code structure that will never be executed. Therefore, dead code can point to a defect in logic, but at minimum, it’s a security risk that needs to be resolved.
There are also benefits to the end user or stakeholder in measuring code coverage. If the application has been tested and 100% of the code has been covered, it provides that warm and fuzzy feeling of delivering something of quality, compared to that of delivering an application with only 60% code coverage attained. This is also why industry functional safety standards like DO-178C, ISO 26262, IEC 62304, IEC 61508, EN 50128, and many others mandate or highly recommend that development teams perform code coverage.
Code Coverage Metrics
Functional standards also guide the type of coverage metrics to attain and some of the various testing methods to use. As previously mentioned, there are coding structures like statements, branches, decisions, and so on, that only get exercised through very specific conditions. These conditions depend on specific variables, and their values at the right moment in time.
Based on the proper conditions, the various execution paths can be tracked and metrics collected. Therefore, you need to create multiple test cases to feed the application with the right data and to create the desired condition.
To collect code coverage metrics, teams can use various test coverage methods like unit testing, system testing, manual testing, and more.
Test Coverage
Since quality assurance (QA) teams have to perform system testing, many organizations use their system test cases to obtain code coverage. However, it’s common for system-level testing not to provide the necessary coverage goals required. It commonly yields 60% coverage, which leaves a lot of room for undiscovered issues. Therefore, teams may end up aggregating coverage from unit testing, integration testing, and manual testing.
Together, these testing methods can get you to 100% code coverage or the desired target. But organizations need to also understand the level of structural code coverage that’s required. Functional safety standards mandate or recommend that code coverage consists of statement, branch, and/or modified condition decision coverage (MC/DC). This is determined by the safety integrity level (SIL) set on your application.
The higher the risk to people and property if failure of the software occurs, the more sets of structural code coverage are required. The strictest code coverage requirements exist in avionics standard DO-178C Level A applications, where code coverage at the assembly code level is in addition to statement, branch, and MC/DC. Fortunately for our customers, Parasoft automates assembly code coverage—also known as object code verification—as part of our solution offering.
Statement Coverage
Statement coverage answers if each statement in the software application has been executed. A statement is a single syntactic unit of the programming language that expresses some action to be carried out.
Here’s a simple statement example: int* ptr = ptr + 5;
Condition Coverage
Condition coverage answers the question: Has each Boolean sub-expression evaluated to both true and false? Conditions evaluate to true or false based on relation operators such as ==, !=, <, >, and others. Different paths of execution are performed based on the evaluated outcome. So, for condition coverage of a condition like (A > 7), you will need two test cases. A test case where A is equal to 0, which satisfies a true outcome, and a test case where A is equal to say 9 satisfying a false outcome.
Decision Coverage
Decision coverage answers the question: Has each non-Boolean sub-expression evaluated both to true and false? Decisions are expressions composed of conditions, and one or more of the logical operators && or ||. To achieve decision coverage for a decision like ((A>7) && (B<=0)), you need test cases that demonstrate a true and false outcome for each decision.
- A test case where A is greater than 7 and B is less than or equal to 0, satisfies a true outcome.
- A test case where A is less than 7 or B is greater than 0 satisfies a false outcome.
It’s important to note that the decision coverage term has been overloaded. For some industries, decision coverage means branch coverage.
Branch Coverage
Branch coverage answers the question: Has each “path” in a condition and decision control structure (if, switch, while catch, and so on) been executed? In some complicated code constructs branch coverage is insufficient, so modified condition decision coverage is recommended in addition to branch coverage.
Modified Condition Decision Coverage (MC/DC)
MC/DC answers the question: Have all conditions within decisions been evaluated to all possible outcomes at least once? It’s a combination of branch, condition, and decision coverage, but much stronger. It ensures that:
- Every control statement takes all possible outcomes at least once.
- Every condition takes all possible outcomes at least once.
- Each condition in a decision has been shown to independently affect that decision’s outcome.
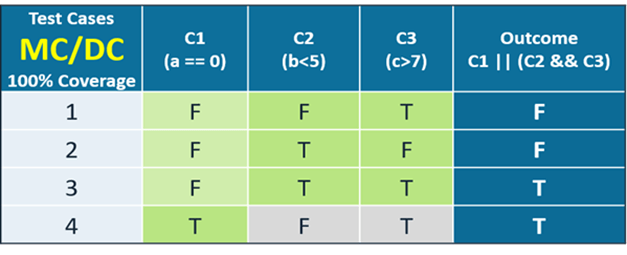
If you take the condition decision statement (C1 || (C2 && C3)) shown in the table, it has:
- Three conditions: C1, C2, and C3
- Two decisions: the OR (||) and the AND (&&)
Based on MC/DC requirements, if condition 1 is false and because the decision is an OR, you need to evaluate condition 2 and 3 to determine the effect on outcome.
However, if condition 1 is true, then the outcome is automatically true and you don’t need to evaluate condition 2 and 3.
There’s a formula for MC/DC in determining the minimum number of test cases required to satisfy 100% MC/DC coverage. It’s the number of conditions plus 1. The table clearly illustrates this.
Other Coverage Types
More coverage types answer the following questions.
- Function coverage. Has each statement of a function in the application been executed?
- Call coverage. Has each function in the program been called?
- Line coverage. Has every line in the program been executed?
- Edge coverage. Has every branch in the program been executed?
- Path coverage. Has every possible route through a given part of the code been executed?
- Entry/exit coverage. Has every possible call and return of the function been executed?
- Loop coverage. Has every possible loop been executed zero times, once, and more than once?
- Block coverage. Has each group of statements in the begin-end or if-else, case, wait, while loop or for loop, and so on been executed?
How to Measure Code Coverage?
Since there are various code coverage structure types, then there are code coverage metrics for each. If your goal or requirement is 100% statement, branch, and MC/DC coverage, you need to fulfill 100% statement, 100% branch, and 100% MC/DC coverage.
There are also coding constructs where test cases cannot be created to hit a particular line of code. For example, a return statement follows an infinite loop. For safety-critical applications where 100% statement coverage is mandated, users can measure and account for that line of code by stepping through it in a debugger. This visual inspection is acceptable and valid as an approach to measuring code coverage. To facilitate the effort needed to collect code coverage it’s important to select the best solution available. Parasoft is that solution.
Step 1. Choose a Code Coverage Tool
As mentioned, code coverage is collected through the use of various testing methods like manual testing, unit testing, system testing, and more. Also, code is instrumented to detect code execution and collect various structural code coverage types like statement, branch, and MC/DC.
Additionally, for safety-critical systems, some stakeholders require performing code coverage on the actual target hardware and certifying the coverage tool for use on safety-critical systems. Therefore, choosing a code coverage tool is an extremely important step to make because it paves the way for a smooth and productive journey.
Step 2. Integrate the Tool
Code coverage solutions from Parasoft seamlessly integrate into IDEs like Eclipse, MSVS, VS Code, and many other editors, making it intuitive to use and deploy. Organizations can also choose to instrument their application and run their existing tests, and in addition, a coverage report is generated.
Most customers integrate Parasoft’s code coverage solution into their continuous integration (CI) pipeline. As part of the build process, the code is instrumented. During the DevOps test phase, code coverage is captured. For safety-critical applications, code coverage can also be captured during code execution on target hardware.
Step 3. Write and Run Tests
Parasoft development and test tools like C/C++test and Jtest automate test case creation for unit testing, integration testing, and system testing. Features like automated unit test case creation can yield up to 80% code coverage or more from the execution of the test cases that are automatically created.
The auto-generated test cases are also smart test cases meaning that the code is analyzed, and test cases are created to expose real defects, like out-of-boundary conditions, null pointers, buffer overflows, divide by zero, and more. This push-of-a-button solution enables huge savings in labor and an incredible increase in productivity. GUI editors and the wizard feature with step-by-step guidance ease creating test cases.
Step 4. Generate Coverage Report
Parasoft code coverage reporting is exceptional. With highlighted, color-coded lines visible within your favorite IDE or code editor, DTP generates code files in color to visually detect lines of code that haven’t been tested and made available for audit purposes. Most compelling is Parasoft’s DTP web dashboard analytics and reporting solution. It displays code coverage charts in progress, risk areas, and focused widgets on statement coverage, branch coverage, and more. This is exactly the comprehensive data that management needs to monitor progress beyond code coverage. It also shows the project’s health and code quality all around.
Step 5. Review and Improve
Because our code coverage and software testing solutions are specifically made to integrate into your CI/CD workflow, teams can review their progress at each sprint review meeting, adjust to changes in requirements, and improve processes that enhance productivity and code quality. Parasoft solutions are built to support modern Agile methodologies. That’s why Parasoft integrates with GitHub, GitLab, Azure DevOps, Bazel, Jira, Jenkins, Bamboo, and more.
The Two Big Traps of Code Coverage
Measurement of code coverage is one of those things that always catches my attention. On the one hand, I often find that organizations don’t necessarily know how much code they are covering during testing, which is surprising! On the other end of the coverage spectrum, there are organizations for whom the number is so important that the quality and efficacy of the tests have become mostly irrelevant.
Code coverage can be a good and interesting number to assess your software quality, but it’s important to remember that it is a means, rather than an end. We don’t want coverage for coverage’s sake. We want coverage because it’s supposed to indicate that we’ve done a good job testing the software. If the tests themselves aren’t meaningful, then having more of them certainly doesn’t indicate better software. The important goal is to make sure every piece of code is tested, not just executed.
What this means is that while low coverage means we’re probably not testing enough, high coverage by itself doesn’t necessarily correlate to high quality. The picture is more complicated than that.
Trap #1: “We Don’t Know Our Coverage”
Not knowing your coverage seems unreasonable to me. Coverage tools are cheap and plentiful. One real issue that teams encounter when trying to measure coverage is that the system is too complicated. When you build an application out of pieces on top of pieces on top of pieces, just knowing where to put the coverage counters can be a daunting task. I would suggest that if it’s difficult to measure the coverage in your application, you should think twice about the architecture.
A second way to fall into this trap happens with organizations that may have a lot of testing, but no real coverage number because they don’t have a code coverage tool or solution that can aggregate the numbers from different test runs. If you’re doing manual testing, functional testing, unit testing, and other types, make sure that the tool you’re using can properly aggregate coverage for all your testing methods.
At Parasoft, we leverage the vast amount of granular data captured with the reports and analytics tool, Parasoft DTP, which provides a comprehensive, aggregated view of code coverage in context. Application monitors gather coverage data directly from the application while it’s being tested and then send that information to DTP, which aggregates coverage data across all testing practices, test teams, and test runs.
If that sounds like a pretty significant amount of information, you’re right! DTP provides an interactive dashboard to help you navigate the data and make decisions about where to focus testing efforts. See the example dashboard below.
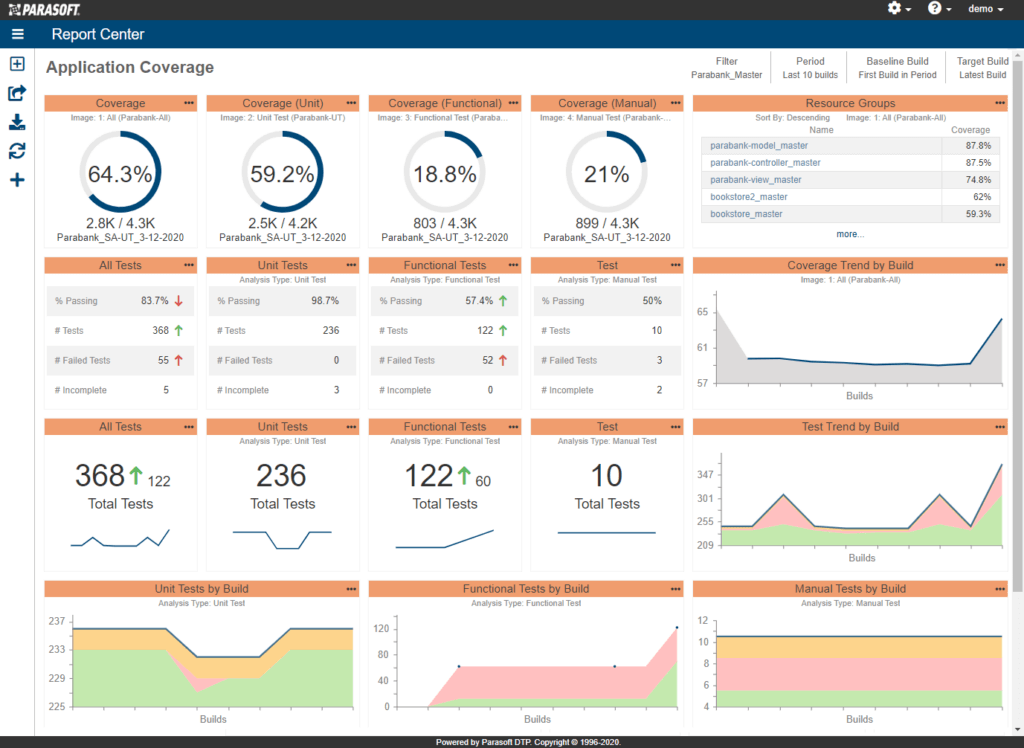
If multiple tests have covered the same code, it won’t be overcounted. Untested parts of the code are quick and easy to see. This shows you what parts of the application have been well-tested and which ones haven’t.
So, no more excuses for not measuring coverage.
Trap #2: “Coverage Is Everything!”
It’s common to mistakenly think that coverage is everything. Once teams can measure coverage, it’s not uncommon for managers to say, “Let’s increase that number.” Eventually, the number itself becomes more important than the testing. Perhaps the best analogy is one from Parasoft’s founder, Adam Kolawa:
“It’s like asking a pianist to cover 100% of the piano keys rather than hit just the keys that make sense in the context of a given piece of music. When he plays the piece, he gets whatever amount of key coverage makes sense.”
Therein lies the problem. Mindless coverage is the same as mindless music. The coverage needs to reflect real, meaningful use of the code.
In certain industries, like safety-critical, for example, the 100% coverage metric is a requirement. But even in that case, it’s all too easy to treat any execution of a line of code as a meaningful test, which may not be true. To determine if a test is a good test, ask the following two basic questions.
- What does it mean when the test fails?
- What does it mean when the test passes?
If you can’t answer one of those questions, you probably have a problem with your test. If you can’t answer either of them, the test is probably more trouble than it’s worth. The way out of this trap is first to understand that the real goal is to create useful, meaningful tests. Coverage is important. Improving coverage is a worthy goal.
Final Insights: Code Coverage as Your Path to Testing Excellence
While code coverage is a valuable metric that can help in identifying untested portions of code and improve the overall quality of a codebase, it should be considered as one aspect of a broader testing strategy. Even achieving 100% code coverage does not necessarily mean the absence of bugs or guarantee the correctness of the software. It alone does not guarantee testing excellence.
It is one of several practices that contribute to a comprehensive testing approach. Code coverage can be part of quality assurance efforts, but other aspects of testing, such as unit testing, integration testing, system testing, and user acceptance testing, are equally important. Testing excellence involves a combination of various testing types, good test design, meaningful test cases, and continuous evaluation and improvement of the testing process.
Comprehensive Code Coverage: Aggregate Coverage Across Testing Practices
Recommended Content

Whitepaper
Related Post + Resources


DEMO WITH Q&A

DEMO WITH Q&A