
AI-driven testing just got smarter. Discover SOAtest 2025.1. >>
Jump to Section
Making Test Data Management (TDM) Easier With Data Simulation
August 8, 2021
6 min read
Ever wondered how best to make test data management (TDM) easier with test simulation? Check out how Parasoft’s virtual test data solution can help you achieve that.
Jump to Section
Jump to Section
To enable parallel integration testing that shifts left functional testing, organizations can leverage Parasoft’s approach to test data management (TDM) that uses AI, machine learning, and virtual test data to replace the need for physical endpoints and databases. Let’s explore how it works.
The Test Data Problem
Validating and verifying software remains one of the most time-consuming and costly aspects of enterprise software development. The industry has accepted that testing is hard, but the root causes are often overlooked. Acquiring, storing, maintaining, and using test data for testing is a difficult task that takes too much time.
We see from industry data that up to 60% of application development and testing time can be devoted to data-related tasks, of which a large portion is test data management. Delays and budget expenditures are only one part of the problem — lack of test data also results in inadequate testing, which is a much bigger issue, inevitably resulting in defects creeping into production.
Webinar: TDM for the Win – How Test Data Management Enables Continuous Testing
Traditional solutions on the market for TDM haven’t successfully improved the state of test data challenges — let’s take a look at some of them.
The 3 Traditional Approaches to Test Data Management
The traditional approaches either rely on making a copy of a production database, or the exact opposite, using synthetic, generated data. There are 3 main traditional approaches.
1. Clone the production database.
Testers can clone the production database to have something to test against. Since this is a copy of the production database, the infrastructure required also needs to be duplicated. Security and privacy compliance requires that any confidential personal information be closely guarded, so often masking is used to obfuscate this data.
2. Clone a subset of the production database.
A subset of the production database is a partial clone of the production database, which only includes the portion needed for testing. This approach requires less hardware but still, like the previous method, also requires data masking and similar infrastructure to the production database.
3. Generate/synthesize the data.
By synthesizing data, there is no reliance on customer data but the generated data is still realistic enough to be useful for testing. Synthesizing the complexity of a legacy production database is a large task, but it removes the challenges of security and privacy that are present with cloning mechanisms.
Get Smart: Use Simulation to Accelerate API Testing
Problems With Traditional Approaches to TDM
First, let’s consider the simplest (and surprisingly most common) approach to enterprise TDM and that’s cloning a production database with or without subsetting. Why is this approach so problematic?
- Infrastructure complexity and costs. Probably the largest downfall of traditional TDM approaches, legacy databases may reside on a mainframe or consist of multiple physical databases. Duplicating just a single production system for a team is an expensive undertaking.
- Data privacy and security. Privacy and security are always a concern when using production databases, and testing environments aren’t often compliant with the necessary privacy and security controls. Masking is the usual solution to handle these concerns, altering sensitive information so as not to reveal any personally identifiable information, but unfortunately, masking is close to impossible without some risk of leaking private information because it’s possible to de-anonymize test data, despite the best efforts of the best test team. Companies that need to comply with GDPR, for example, might struggle to convince regulators that their cloned test environment meets the required privacy controls.
- Lack of parallelism and data collisions. Given infrastructure costs, there are a limited set of test databases available, and running multiple tests in parallel raises concerns about data conflicts. Tests might delete or alter records that other tests rely on, for example. This lack of parallelism means testing becomes less efficient and testers have to worry about data integrity after each test session.
- Subsetting doesn’t do much to help. Although it might be possible to create a manageable subset that requires less infrastructure, it’s a complex process. Referential integrity has to be maintained and privacy and security issues remain in the subsets.
- Synthesizing data cures privacy concerns, but requires lots of database and domain expertise. Creating and populating a realistic version of a test database requires intimate knowledge of the existing database and the ability to recreate a synthetic version with data that is suitable for testing. So while this approach solves many of the security and privacy concerns, it requires much more development time to create the database. Infrastructure issues remain if the test database is large, and parallelism might be limited depending on how many test databases can be used simultaneously.
Solving Test Data Management Problems With Data Simulation
The simplified and safer approach to test data management that we offer at Parasoft in our SOAtest, Virtualize, CTP virtual test data tools is much safer and solves these traditional problems. So how is it different from the traditional approaches?
Test the Untestable: Alaska Airlines Solves the Test Environment Dilemma
The key difference is that it collects test data by capturing traffic from API calls and JDBC/SQL transactions during testing and normal application usage. Masking is done on the captured data as necessary, and data models are generated and displayed in Parasoft’s test data management interface. The model’s metadata and data constraints can be inferred and configured within the interface, and additional masking, generation, and subsetting operations can be performed. This provides a self-service portal where multiple disposable datasets can easily be provisioned to give testers full flexibility and control of their test data, as you can see in the screenshots below:
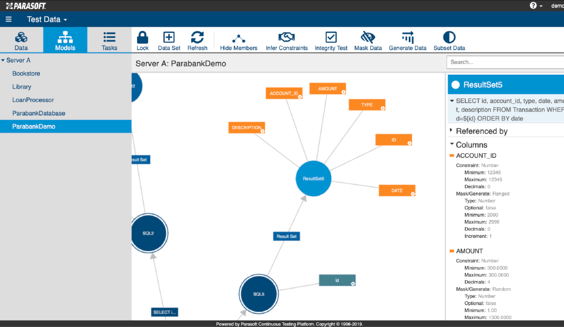
Parasoft’s virtual test data management technology is augmented by service virtualization, where constrained back-end dependencies can be simulated to unblock testing activities. A good example would be replacing a reliance on a shared physical database by swapping it with a virtualized database that simulates the JDBC/SQL transactions, allowing for parallel and independent testing that would otherwise conflict. Parasoft’s test data management engine extends the power of service virtualization by allowing testers to generate, subset, mask, and create individual customized test data for their needs.
By replacing shared dependencies such as databases, service virtualization removes the need for the infrastructure and complexity required to host the database environment. In turn, this means isolated test suites and the ability to cover extreme and corner cases. Although the virtualized dependencies are not the “real thing,” stateful actions, such as insert and update operations on a database, can be modeled within the virtual asset. See this conceptually below:
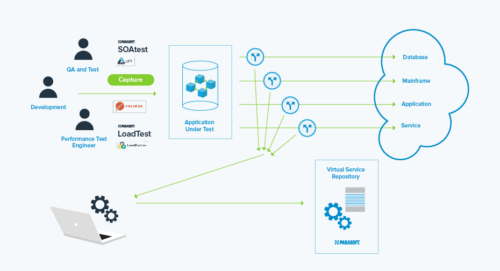
The key advantage of this approach is that it avoids the complexities and infrastructure costs of cloning databases, allowing API level testing (like integration testing) much earlier than with other test data methods.
A few other benefits to this approach include:
- Because it doesn’t require underlying database infrastructure, it can usually run locally on developers’ and testers’ workstations.
- Isolated test environments unique to each tester mean that there are no data collisions or concerns about data integrity for a shared test database. Testing becomes highly parallel, removing the waiting time and wasted cycles of traditional approaches.
- Testers can easily cover corner cases that might cause corruption and other problems, on a test database. Since each test environment is isolated, testers can easily perform destructive, performance, and security testing, without concerns integrity of a shared resource.
- It’s easy to share tests and data among the team to avoid duplicating effort, and API tests are customizable for other purposes such as security and performance testing.
- Using virtualized servers eliminates the complexity of the underlying database schema. Stateful testing is available to provide realistic scenarios.
- By capturing only the data you need with dynamic masking, you no longer need a cloned database, placing the focus of integration testing on the APIs, rather than maintaining a shared, cloned database.
Testing on the physical database will still be necessary but only required towards the end of the software delivery process when the whole system is available. This approach to test data doesn’t eliminate the need for testing against the real database entirely but reduces reliance on the database in the earlier stages of the software development process to accelerate functional testing.
Summary
Traditional approaches to test data management for enterprise software rely on cloning production databases and their infrastructure, fraught with cost, privacy, and security concerns. These approaches aren’t scalable and result in wasted testing resources. Parasoft’s virtual test data solution puts the focus back on testing and on-demand reconfiguration of the test data, allowing for parallel integration testing that shifts left this critical stage of testing.
The Solution to Your Test Data Management Headaches
Recommended Content

Whitepaper
Related Post + Resources

ROI Calculator

