
AI-driven testing just got smarter. Discover SOAtest 2025.1. >>
Jump to Section
How to Take a Free Service Virtualization Tool & Scale It Into a Full DevOps Deployment
July 12, 2023
11 min read
Service virtualization is typically used to connect applications that rely on third parties' cloud, SOA, or API. Learn how to expand a free service virtualization tool into a comprehensive DevOps implementation by reading this blog post.
Jump to Section
Jump to Section
The best way to bring service virtualization into your organization is step by step. Use it where it’s most valuable to lower the total cost of testing and gain the power to control your test automation process with a fully automated DevOps workflow.
Let’s use an analogy. When you decide it’s time to adopt a healthy lifestyle, you might do some research and end up with advice like, “Stop drinking alcohol! Start eating kale! Go to bed at 8 o’clock! Walk five miles every day!” While it might make sense to embrace all of these activities to adopt a healthy lifestyle, if you try to adopt them all at once, you’ll probably fail. Instead, you need to go step by step. Add an extra exercise here. Make a healthy food choice there. Slowly get yourself up to a level where you can develop healthy habits like a pro.
Service virtualization is no different. I’ve helped numerous customers over the years adopt this valuable DevOps enabler. Most organizations want to do the big bang approach—immediately bring in a fully deployed solution that spans across multiple teams and is already integrated as a part of their continuous delivery pipeline.
While all of these things are essential to fully realizing the potential ROI that service virtualization can provide, if you try to do it all on day one, then you’re probably not going to be able to effectively scale into your full DevOps deployment. So how do you get there?
In this blog, I’ll share just that. We’re going to follow one individual, from her single free service virtualization license all the way to her organization’s full deployment of service virtualization, integrated into their DevOps workflow. This is based on a true story, but for the sake of anonymity, we’re going to call this individual Sally.
Step 1: Get Started With Parasoft Virtualize for Free to Increase Efficiency

Meet Sally the developer. Sally is smart and able to develop at a much faster rate than her colleagues. She started using mocks to isolate herself during the testing phase but was spending a lot of time developing the type of logic that she needed to build into those systems because the actual applications she was stubbing out were complex.
So, she learned how service virtualization could create a more complicated virtual service in a noticeably short amount of time. She downloaded the free version of Parasoft Virtualize to get service virtualization for free, which enabled her to start creating virtualized services and easily modify them as the actual services were undergoing change. As a result, she could do all of her testing and development in a completely isolated environment.
Step 2: Enable Adoption Across the Team Entry Barrier
As she discussed these advantages with some of her coworkers, they too wanted to leverage the services she had created because they were common services between the different developers. They could simply point their applications at Sally’s machine and reap the benefits.
They also got free service virtualization with Parasoft Virtualize and started making new services, adjusting those services, and consuming those services all from their free desktops. The team made significant progress in development and testing because they were able to reduce a lot of the bottlenecks that had been present in the environment. The team became popular for its agility and got all of the best projects.
Step 3: Unleash the Full Potential of Parasoft Virtualize
Management approached Sally’s team. They were curious about the service virtualization solution that the team was using to help them build and test the applications more rapidly. They wanted to have a discussion about its practical application in the larger environment. There had been some buzz around outages in the integration and production environments caused by legacy applications. The applications relied on a series of Oracle databases and a complex ESB and a mainframe.
Those systems were difficult to test against for a series of reasons. Sally and her team were able to show that it was easy to simulate the services behind the ESB because they were basic REST and SOAP services and a couple of JMS and MQ with homegrown XML. To tackle the legacy hardware, they needed to supercharge their service virtualization desktop, so they upgraded to the full version of Parasoft Virtualize.
 At this point, they were able to easily apply service virtualization for the different challenges present in the use cases described by management. It took a few days to make sure that the virtual services satisfied all the different use cases, but they were able to unblock all of the challenges that they had in those environments. This was one of the key turning points for the service virtualization movement in Sally’s organization because they were able to leverage Sally’s team’s expertise with basic service virtualization to tackle more complicated challenges that had real costs associated with them.
At this point, they were able to easily apply service virtualization for the different challenges present in the use cases described by management. It took a few days to make sure that the virtual services satisfied all the different use cases, but they were able to unblock all of the challenges that they had in those environments. This was one of the key turning points for the service virtualization movement in Sally’s organization because they were able to leverage Sally’s team’s expertise with basic service virtualization to tackle more complicated challenges that had real costs associated with them.
Step 4: Deploy a Virtualize Server for Optimized Uptime & Availability
As the team became more popular, it became clear that they needed to scale their deployment. If one of the team members had to shut down the machine or go on vacation, it would affect users hitting the virtual services. Sally decided it was time to upgrade their deployment architecture once again, and they procured a virtualization staging server.
This allowed each member of the team to combine their effort for a complete simulated testing ecosystem. The server was always on and acted as a virtual artifact library. It was connected to source control, so as different versions of the services were deployed to the server, they would automatically be checked in. This allowed the team to have a central point of truth for all virtual assets. No one had to guess where the most recent version was.
The team happily hummed along for several months solving big and meaningful challenges for the organization. It grew in size with a few more members. To boost the team’s visibility and awareness—and increase the size of their budget—Sally implemented the “Hoo-Rah” program.
Every time the team built something with quantifiable ROI, they kept track of the gains and sent out a public email explaining what they had done, and which teams had benefited. Examples of these “hoo-rah”s were:
- The team simulated the stormtrooper SOAP services and the extension table in the main Oracle database and enabled an automated process to provision and test the payments service’s 111 combinations. This increased test throughput and automated test execution that saved them $27,950 for a project cycle.
- The team was able to simplify a cloud migration initiative by simulating services that were not ready to be moved into the cloud. This allowed the transformation to happen two weeks ahead of schedule because they were able to do validation in phases and still function even though pieces were missing. This saved them $45,875 in man hours for the project.
- The team proactively managed a third-party service change by creating a virtual representation of the new service, delivering access to dev/test 2-6 weeks earlier. This change management reduced unplanned downtime associated with third-party services (approximately 30%) for a program save of $27,146.
- The team simulated the member search service on the Mainframe that provided unique members when calling for accounts, significantly simplifying the test requirements for the process flow. Teams now have control over the data for the mainframe and database, and they can insert any type of behavior they’re looking for. This is projected to significantly reduce 15,000 hours of unplanned outages from middleware.
- The team simulated the member search service on the mainframe that provided unique members when calling for accounts, significantly simplifying the test requirements for the process flow. Teams now had control over the data for the mainframe and database, and they could insert any type of behavior they were looking for. This is projected to significantly reduce 15,000 hours of unplanned outages from middleware.
These “hoo-rah” emails were vital for bringing additional teams into the fold and helped the key stakeholders of the business understand the importance of service virtualization to the test automation process.
Getting Value From Negative Simulation
While performing an audit of a critical application, a member of the security team discovered a potential attack vector in the system that could be exploited and cause not only sensitive customer data to be leaked, but also force the organization out of compliance. If not remediated quickly, the organization would be forced to update the compliance committee and start the penalty process.
The team realized that if they could remediate the defect within a specific time window, they could push the changes to the production environment and all would be well. The challenge was that in order to successfully reproduce the issue, they had to put many of their third-party payment systems into a state where they would provide back various error conditions and intentionally leak PII or customer data.
The team didn’t have the ability to force these systems, which were outside of their control, into the state that they needed to in order to expose the defect and validate the fixes they would put in place. Sally was called in the middle of the evening and asked to go to work.
The team made quick work of reusing existing virtual services that they had created for these third-party payment systems and putting them into a state where they would start returning negative behavior. Because the application didn’t have to be redeployed, they could simply modify the behavior as the developers were making their changes and flush out all of the different combinations that led to the potential exploit. Needless to say, the team was successful in delivering a hot patch into production that saved the company millions.
Step 5: Enable Scalability of Service Virtualization Across the Enterprise
The management team then took the next valuable step for their organization: creating a dedicated service virtualization center of excellence that could be leveraged to build virtual services whenever new challenges arise. Sally, of course, was the natural fit to lead the team.
Sally started building processes around onboarding virtualization initiatives and creating acceptance criteria, so the team itself didn’t become a new bottleneck. Governance became an important part of the conversation.
The team set up a series of five roles and responsibilities to ensure each virtualization project was successful.
- The tester. Whenever you create a virtual service, you need to have a reason for virtualizing the particular component. Quite often the team would get requests to simulate an unreliable application in the environment. When they had the initial conversation with the requester, they would ask, “What is it that you can’t do?” This question is critical because you must have clearly defined acceptance criteria in order to have a definition of “done” for a virtual asset. The tester becomes an essential part of this process because they can define which test cases need to execute successfully and the virtualization team will know they’ve created a successful virtual asset when that is accomplished.
- The developer. Virtual assets can be created with little to no understanding of the application that you are virtualizing. But, in order to create a virtual service with a minimal amount of effort, it helps to have domain knowledge about the application you are simulating. So, the developer becomes an essential part of the virtual asset creation process, giving explanations of how the services function so that when the virtual services are created, there’s an understanding of why it functions the way it does.
- Test data management. It’s arguable that many service virtualization challenges are actually test data challenges at the core, so test data management teams become important when building virtual assets. Most virtual assets are created by record and playback. When the test cases are identified and the behavior is agreed upon, it’s important that the environment in which you’re going to record has the proper test data at the time of recording. So, while test data management teams in this case had a minimal role in the virtualization process itself, it was crucial to bring them into the process before creating the initial offering.
- Operations. Virtual services replicate real services, so if you created the virtual service right, a user may not actually know they’re hitting simulation. As a result, the virtual service needs to be available at an endpoint defined in the environment where the actual service is located. This can often be a roadblock to the virtualization process because many people won’t have access to reconfigure the necessary connections to point the application at the virtual services endpoint. Parasoft Virtualize uses a mechanism called the proxy, which allows a service to communicate through a man in the middle, that Sally’s team could control. But getting that initial connection set was the responsibility of the ops team. Identifying the operations resource ahead of time and making the upfront contract that this initiative would be taking place was the best way to ensure that when it came time to connect all the pipes together the team would be ready and able to understand what was taking place.
- Leadership. In order for any service virtualization project to be successful, management has to buy in. This wasn’t difficult in Sally’s case because they started from the ground up and had proved significant value, but it was important to maintain continued focus from leadership for the team to function productively.
Setting up these roles was critical to the success of the service virtualization team, clarifying the needs to make the virtualization projects successful. Each member of the service virtualization team had Parasoft Virtualize desktop software. They would create the virtual services onto the desktop, and then make them available to users.
Step 6: Collaboration & Continuous Integration Across the DevOps Pipeline
Sally’s service virtualization center of excellence team became popular with developers and testers. Many started asking for access to Parasoft Virtualize so they could make their own prototypes and validate negative and positive scenarios.
Sally had the infrastructure to support it, but she didn’t necessarily need to give them the heavy hammer that was the professional desktop version. She upgraded their infrastructure again and included Parasoft’s thin-client interface to fully enable their DevOps workflows. This centralized dashboard gave access to any user in the organization and enabled them to create virtual services and test cases right from their browser.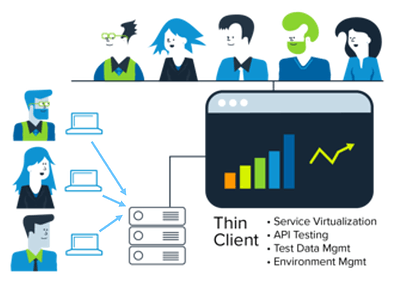
This evolution of the deployment created a hybrid model in which individual team members could act in a federated way, creating their own virtual services for their needs, accessing them, modifying them, and so on. And when it came time to integrate those virtual services into the larger architecture, they had a mechanism to collaborate with the virtualization center of excellence. The team could add additional servers to support the load and snap in performance servers when the performance team got on board.
At this point, Sally had a comprehensive library of virtual assets and corresponding automated test cases. She had a library of test data feeding into both of these test artifacts. The majority of the actual service creation was taking place by the individual teams, and Sally’s team was primarily responsible for orchestrating all of those different virtual services into an “environment.”
The environment was really just a template of virtual assets, test cases, and test data built into a specific configuration in order to satisfy a testing initiative. They built many of these environment templates and aligned them to the different applications in the organization.
Whenever an application needed to be tested and the real environment wouldn’t suffice, the virtualization center of excellence would spin off an environment of different virtual services and allow the team members to test. The teams became more and more reliant on virtual services as a part of their test execution, and it was a natural transition into the continuous delivery pipeline.
The final and fully-realized deployment for service virtualization at Sally’s organization looked like this: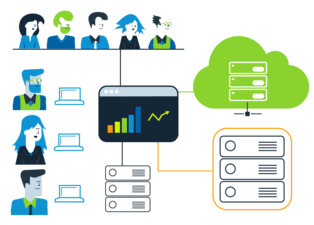
Individual team members would create the virtual services and test cases within their browsers. If the virtual services needed to be updated or additional logic needed to be added, the virtualization COE would handle that with their professional desktops.
The virtual services and test cases would then be combined inside of the thin client interface. When those environments needed to be available, their build system would call and deploy them either into the cloud or onto dedicated servers. The automated test cases would then kick off, the results would be sent to their aggregated dashboard, and the dynamic environment would be destroyed.
Getting to a Fully-Realized Virtualization Deployment
True continuous testing enabled by service virtualization isn’t something that happens overnight. This story is real and it’s all possible with service virtualization. But it requires the organization to be brought in and start from the ground up, just like Sally did. By the way, she’s now on the executive board.
This approach is the best way to bring service virtualization into your organization—step by step, utilized where it’s most valuable. Everybody’s exact journey will be different, but the end results should be the same:
- Lower the total cost of testing.
- Gain the power to control your test automation process.
Build Reliable & Predictable Service Simulations With Parasoft Virtualize
Recommended Content
