
AI-driven testing just got smarter. Discover SOAtest 2025.1. >>
Jump to Section
Risk and Quality Debt: What You Don’t Know Can Hurt You

June 20, 2023
11 min read
Many unknowns in the development equation are eliminated by knowing where the risk is and how each code change affects your system's security. Therefore, quality and security debt may be overcome with the appropriate emphasis. Learn how to prioritize and effectively reduce the risk associated with code modifications.
Jump to Section
Jump to Section
When it comes to assessing the risk of a code base, it’s not a single bullet magic number a simple go/no-go traffic light. Risk is multi-dimensional and multi-variant. It’s measured differently for different organizations.
You probably already know where the high-risk or bad parts of the code are. They’re the parts of the code always changing—little tweaks here and there to fix little issues that seem innocuous in themselves but typically represent the layering of features on top of poor design. This is why making changes to existing code is the leading cause of introducing defects into an application.
But we also know that change is constant. You never implement everything completely or correctly the first time. Additionally, as developers layer on top of the existing code, knowledge of each use case and scenario gets lost, complexity increases, and the code becomes more and more risky. It’s these changes that provide the key to applying context to risk.
Just as important as the visibility into risk itself is understanding how to deal with it. How to prioritize remediation actions to achieve an acceptable level of risk while minimizing the impact on team velocity. This post looks at just that: how to assess the risk of code changes and how to efficiently prioritize and mitigate the risk.
Uncovering the Hidden Costs of Quality Debt
Quality debt, or technical debt, in software development, can impose significant hidden costs on a project. While the immediate impact of taking shortcuts or compromising code quality may seem minimal, the long-term consequences can be substantial. Here are some of the hidden costs associated with quality debt.
Increased Support & Maintenance Costs
When you have a code base that is poorly designed, lacks proper documentation, or violates best practices, it becomes difficult to maintain over time. Developers spend more effort understanding and navigating the codebase, leading to decreased productivity and increased maintenance costs on software products.
The longer quality debt remains unaddressed, the more products or services are prone to defects, glitches, and failures, requiring additional support and maintenance efforts. This not only strains the resources of customer support teams but also demands a significant allocation of time and money to fix issues. These ongoing costs erode profitability and divert resources away from other critical business initiatives.
Employee Frustration & Burnout
The repeated need to fix issues caused by technical debt can lead to frustration, reduced productivity, and burnout among team members. Imagine subjecting a team of developers to debug or apply fixes on a product repeatedly. If it’s not a security breach today, it’s total glitches in uptime, and the list goes on. Having developers in this kind of loop can trigger a mass exodus from an organization, affecting workforce stability and expertise.
Bug & Defect Accumulation
Low-quality code is more prone to bugs and defects. When shortcuts are taken or thorough testing is skipped, errors can go undetected and accumulate over time. Identifying and fixing these backlogs of technical debts becomes progressively difficult, resulting in increased debugging time.
The cost of addressing these bugs and defects in the future can far exceed the initial time saved by taking shortcuts. In addition, bug and defect accumulation also results in delayed delivery of products and affects the agility of the team. This is usually the case when the codebase has been made more complex with easy tweaks here and there.
Decreased Customer Satisfaction & Hindered Innovation
Quality debt can impact the end user experience negatively. Users may encounter more frequent bugs, experience slower performance, or face usability issues. This can result in customer dissatisfaction, negative reviews, and potential loss of business. In addition to affecting customer satisfaction, accumulated quality debt limits the software’s ability to adapt and evolve.
Adding new features or integrating with other systems becomes challenging, hindering innovation and scalability. When companies have quality debt issues, it may also discourage developers from suggesting improvements or introducing innovative ideas, as they’re burdened with existing issues.
Regulatory Compliance & Legal Consequences
In certain industries, quality debt can result in noncompliance with regulatory standards, leading to legal consequences and potential financial penalties. Failure to meet quality and safety regulations can harm the brand’s reputation and erode customer trust, further exacerbating the hidden costs.
Determining Multi-Variant Risk
Risk isn’t a single number or a project-level traffic light. But, as shown in the pie chart below, Parasoft does use easily associated traffic light colors in the UI as a categorization of the codebase and guidance on where real and potential problems exist.
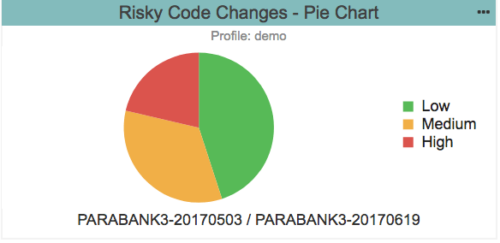
The categorization of risk is both multi-dimensional and multi-variant, bringing together quality metrics from software testing techniques like static analysis and code coverage. No single technique provides the value for a specific dimension but rather provides a value for a formula. For example, code coverage isn’t a good number to use on its own because you could have 100% coverage but only a small number of tests doing anything meaningful. Instead, think about what you’re using code coverage to tell you, such as asking, how well is my code tested? Then, augment that with more data to get a more meaningful analysis.
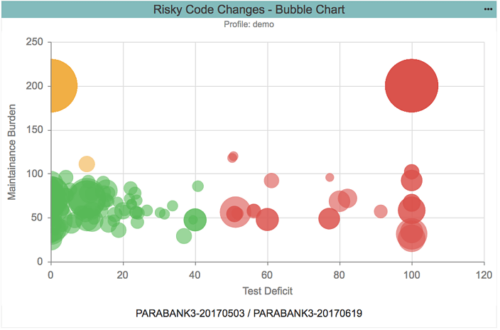
The bubble chart above illustrates the categorization of risk based on two dimensions. This is also shown in the screenshot below.
- Maintenance burden. Combines Halstead volume and strict cyclomatic complexity, the number of lines of code, and the ratio of code to comments to quantify how maintainable and understandable the code is.
- Test deficit. Uses the number of tests, number of methods, and code coverage to quantify how well the code has been tested.
Code that has been poorly tested has a higher test deficit and is categorized as high risk (red). Code that’s well-tested and well-constructed has a lower maintenance burden and is categorized as low risk (green).
Volatile Codebases, Where Every Change Is a Risk
During the heat of development, your codebase is in a constant state of flux and every single line of code change presents an unknown risk. Will it break a fundamental feature? Does it introduce a security flaw? The less information, the greater the risk. Code coverage needs to be used intelligently to predict where to focus testing resources. However, even with increased coverage and testing, there’s still an additional risk that accumulates over time.
The change in the codebase gives us the third, and most important, risk dimension: time. Not time in the traditional sense, but time as it relates to the builds and the changes between them. Focusing on the parts of the codebase that have changed between builds provides the ability to concentrate on addressing the code that is both the highest risk and most relevant as the team works in this part of the codebase.
Is the Burden of Quality Debt Slowing You Down?
Reused and legacy code have their own burden, particularly for security. Each submitted or modified line of code adds to this debt if there aren’t adequate checks to maintain or improve the quality baseline. Getting out of this debt, like any debt, requires focus and a commitment to reduction. Also, like any debt, how does one know where to make cuts to save unless you know where money is being spent?
Once you identify the code with the highest risk and highest priority, consider the amount of work required to mitigate the risk. This is the fourth and final dimension: quality debt. In the bubble chart above, quality debt is represented by the size of the bubble—the bigger the bubble, the more known issues that need to be addressed. In our example, the quality debt is a combination of high-severity static analysis violations (including violations of set thresholds for code metrics) and test failures normalized by the number of logical lines of code.
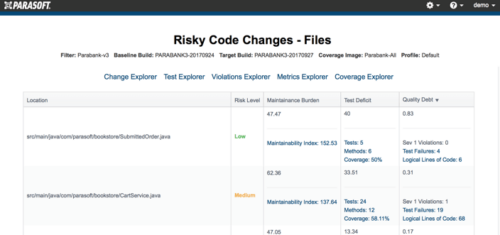
But That’s Not How I Measure Risks!
Not every organization is going to follow the same quality practices or agree on what factors to take into consideration when calculating the dimensions. You need to be able to configure and create your own definition of risk.
The example in this blog is available for users on the Parasoft Marketplace, enabling you to use it out of the box, extending and modifying to meet your specific needs. Starting with the example, you can customize the static analysis, metrics thresholds, and risk categorizations to suit your organization.
Strategies for Tackling Quality Debt
It’s important for development teams to manage and reduce quality debt over time to maintain software quality, ensure efficient development processes, and minimize long-term costs. To effectively tackle quality debt, it’s crucial to adopt strategies that address its prevention, reduction, and continuous improvement. Below is a breakdown of some strategies organizations can adopt to tackle quality debt.
Prevent Quality Debt
Preventing quality debt is a proactive approach that focuses on avoiding the accumulation of technical debt in the first place. By adopting the following practices, software development teams can reduce the likelihood of incurring significant quality debt.
- Robust requirements analysis. Invest time and effort upfront to thoroughly understand project requirements, constraints, and stakeholders’ expectations. Clearly defining the scope, functionality, and performance goals helps lay a strong foundation for development.
- Agile development practices. Agile methodologies promote iterative development and emphasize continuous feedback loops. This approach enables early identification and resolution of quality issues, preventing them from escalating into significant technical debt.
- Code reviews and pair programming. Encourage a culture of code reviews and pair programming within development teams. Regularly reviewing code and collaborating on development tasks enhances code quality, reduces the likelihood of introducing technical debt, and promotes knowledge sharing.
- Consistent coding standards. Establish and enforce coding standards to ensure uniformity and maintainability of the codebase. This includes guidelines for naming conventions, code formatting, and documentation practices. Automated code analysis tools provided by Parasoft can assist in enforcing these standards.
Prioritize Quality Debt Reduction
Addressing technical debt requires a proactive and systematic approach. While it may be tempting to prioritize new feature development over debt reduction, neglecting technical debt can have severe consequences. Here are some strategies to prioritize and reduce technical debt effectively.
- Identify and assess. The first step in prioritizing quality debt reduction is to identify and assess the areas of concern within your software project. Conduct regular code reviews, analyze bug reports, and gather feedback from developers and users. Look for code smells, complexity hotspots, and areas where the system is prone to failures or performance bottlenecks. Evaluate the impact and potential risks associated with each technical debt item. By understanding the debt landscape, the team can make informed decisions about where to focus efforts.
- Prioritize. Not all technical debt will have an equal impact on the overall outcome or performance of your software project. It’s essential to prioritize debt based on its potential impact, severity, and urgency. Start by considering the areas that significantly impact code quality, system stability, and user experience. For example, if there are critical bugs affecting core functionality, it’s crucial to address those first. In addition, it’s also essential to engage with key stakeholders to align priorities with business goals. Their input can help determine which debt items have the most significant impact on customers, revenue, or the overall success of the project.
- Test and automate. Investing in automated testing is crucial for effective debt reduction. Implementing a robust suite of tests helps catch regressions and ensures code quality over time. Integrating automated unit tests, integration tests, and acceptance tests into your development process all contribute to the reduction of technical debt.
Consider implementing a continuous integration and delivery (CI/CD) pipeline that automates code quality checks, testing, and deployment processes. This ensures that every change made to the codebase is tested thoroughly before being deployed, preventing the accumulation of new debt. Automated testing solutions significantly streamline the development and deployment process, enabling you to focus more on debt reduction and less on manual testing and error-prone tasks.
- Plan incremental improvements. Technical debt reduction should be approached incrementally. Trying to tackle all debt at once can be overwhelming and counterproductive. Instead, break down larger debt items into manageable tasks and plan them incrementally. Create a roadmap that outlines the specific debt reduction tasks to be addressed in each development cycle or sprint. Balance debt reduction with new feature development, allocating time and resources accordingly. By taking small, manageable steps, you can steadily reduce debt while still delivering value to users.
Refactor Code Continuously
Code refactoring is a disciplined technique that improves the internal structure and design of the codebase without changing its external behavior. Continuous code refactoring is an essential practice for tackling quality debt as it helps maintain code quality, reduce complexity, and improve maintainability. Here are some key considerations for effective code refactoring.
- Refactor as a regular practice. Integrate code refactoring as an integral part of the development cycle. Encourage developers to refactor code during feature development, bug fixing, and code review stages to address technical debt incrementally.
- Test-driven refactoring. Adopt a test-driven development (TDD) approach where automated tests are written first before refactoring. This ensures that any changes made during refactoring do not introduce new bugs or regressions. The existing tests serve as a safety net, providing confidence that the code behaves as expected after refactoring.
- Refactor tools and IDE support. Utilize refactoring tools and integrated development environments (IDEs) that offer automated refactoring capabilities. These tools can simplify and expedite the refactoring process, reducing the effort required for quality debt reduction.
- Monitor and measure refactoring efforts. Keep track of the refactoring activities you undertake and their impact on code quality and maintainability. Metrics like code complexity, code coverage, and bug rates can help evaluate the effectiveness of refactoring efforts.
Optimize Testing Procedures & Documentation
Effective testing procedures and documentation play a crucial role in minimizing quality debt and ensuring software reliability. Your organization can tackle quality debt by optimizing testing procedures and documentation through the following strategies.
- Define and standardize testing processes. Establish clear and well-defined testing procedures that cover different types of tests, including functional, integration, performance, and security testing. Standardize these processes across teams and projects to ensure consistency and reduce the risk of overlooking critical testing activities.
- Prioritize test coverage. Analyze the application or product under test to identify critical areas that require thorough testing. Prioritize test coverage in these high-risk areas to minimize the chances of defects slipping through unnoticed. Use techniques like risk-based testing to allocate testing resources effectively and focus efforts where they’re most needed.
- Document testing procedures. Create comprehensive and up-to-date documentation that outlines testing processes, test cases, and test data requirements. Make the documentation easily accessible to the entire team to ensure consistent testing practices. This documentation should also include guidelines for writing effective test cases and steps for reproducing reported issues.
- Foster collaboration between development and testing teams. Encourage close collaboration between development and testing teams to foster a shared understanding of quality goals and objectives. Establish effective communication channels and encourage regular feedback and knowledge sharing. Collaboration helps bridge the gap between development and testing, leading to better test coverage, quicker bug resolution, and reduced quality debt.
Benefits of Addressing Quality Debt
Addressing quality debt is crucial for the long-term success of software projects. Here are some key reasons why you should start addressing quality debt in your company.
Customer Satisfaction & Retention
When companies address quality debt, they can significantly improve customer satisfaction. By investing in software quality, they can deliver a product that performs better, has fewer bugs, and offers a smoother user experience. Users will appreciate the increased reliability and stability of the software, resulting in higher satisfaction levels and positive public reviews. Satisfied customers are more likely to continue using the software, renew licenses or subscriptions, and become advocates by recommending it to others.
Competitive Advantage
In a competitive market, addressing quality debt gives software development companies a distinct advantage over their rivals. By focusing on software quality, companies can offer a product that stands out from the competition. Software with fewer issues and better performance can attract new customers who value reliability and efficiency. It can also help retain existing customers who may be considering alternatives. By emphasizing quality, companies can differentiate themselves in the market and position their software as a preferred choice.
Reduced Maintenance Costs
One of the significant drawbacks of quality debt is its impact on maintenance costs. Software with poor quality often requires frequent bug fixes, patches, and updates, which can be time-consuming and costly. By addressing quality debt proactively, companies can minimize the need for ongoing maintenance, which produces a higher quality codebase, reduces the occurrence of bugs, and enhances the software’s overall stability. This, in turn, leads to lower maintenance efforts and costs, allowing companies to allocate their resources more efficiently to new feature development, innovation, and other business priorities.
Efficient Development Process
Accumulated quality debt can hamper the development process in several ways. It can cause delays, increase the time spent on debugging, and create technical complexities that slow down progress. By addressing quality debt, companies can streamline their development process. Developers can work with cleaner code that is easier to understand and maintain. This results in increased productivity as they spend less time on troubleshooting and more time on creating new features and functionality. The streamlined process helps teams meet deadlines, deliver software on time, and iterate faster based on user feedback.
Long-Term Scalability
Neglecting quality debt can impede a software product’s scalability. As the software evolves and new features are added, the underlying poor-quality code can become a significant barrier to growth. By addressing quality debt, companies ensure that their software has a solid foundation for long-term scalability. They can refactor and optimize the codebase, making it more flexible and adaptable to changing business needs and technological advancements. This allows for easier maintenance, extension, and integration of new functionalities, enabling the software to scale effectively as the company expands or user requirements evolve.
Conclusion
Balancing budgets, schedules, and quality goals with adequate security measures while satisfying customers is a tall order with risks at every turn. However, automation of quality practices and process intelligence helps guide where to best spend resources. Understanding where the risk lies and how each code change impacts your baseline quality and security, reduces many unknowns in the development equation. Development teams can beat quality and security debt with the right focus.
The Business Value of Secure Software
Recommended Content

Whitepaper


